
 About Me
About Me
Xize Cheng (成曦泽) is a fourth-year doctoral candidate at the School of Computer Science and Technology, Zhejiang University, expecting to graduate in June 2026. He is advised by Professor Zhou Zhao. I am actively looking for academic collaboration, feel free to drop me an email.
In 2024, I lead or participate in the following research topics:
- Large Language Models(LLMs): Spoken Dialogue Systems / Audio Large Language Models
- Audio Understanding: Sound Separation Model / Audio-Visual Speech
🔥 News
- 2025.01: 🎉🎉 4 papers (2 first author) are accepted by ICLR 2025!
- 2024.09: 🎉🎉 3 papers are accepted by NeurIPS 2024!
- 2024.09: 🎉🎉 1 papers (1 co-first author) are accepted by EMNLP 2024!
- 2024.07: 🎉🎉 2 papers (1 first author & 1 corresponding author) are accepted by ACL 2024!
- 2024.05: 🎉🎉 3 papers (2 co-first author & 1 corresponding author & 1 oral presentation) are accepted by ACMMM 2024!
- 2024.03: 🎉🎉 2 papers are accepted by ICML 2024!
- 2024.01: I start my internship at Alibaba, DAMO Academy, Tongyi Lab.
- 2023.10: 🎉🎉 I am awarded the National Scholarship (2023, Graduate student). Top 0.1% at Zhejiang University.
- 2023.09: 🎉🎉 1 paper is accepted by EMNLP 2023!
- 2023.09: 🎉🎉 1 paper is accepted by NeurIPS 2023!
- 2023.07: 🎉🎉 1 paper (1 co-first author) is accepted by ACMMM 2023!
- 2023.05: 🎉🎉 3 papers (1 first author) are accepted by ICCV 2023!
- 2023.06: AV-TranSpeech comes out! Media coverage: PaperWeekly and ByteDance.
- 2023.05: OpenSR will be presented in an oral presentation at ACL 2023!
- 2023.05: 🎉🎉 7 papers (1 first author & 2 co-first author, & 2 oral presentation)are accepted by ACL 2023!
- 2023.03: We created the first Audio-Visual Multi-lingual Speech Translation dataset AVMuST-TED!
- 2022.10: I was awarded the Outstanding Graduate Student and Triple Excellence Graduate Student of Zhejiang University!
- 2021.03: I started my internship at Taobao as an algorithm intern, conducting multi-modality research.
📝 Publications
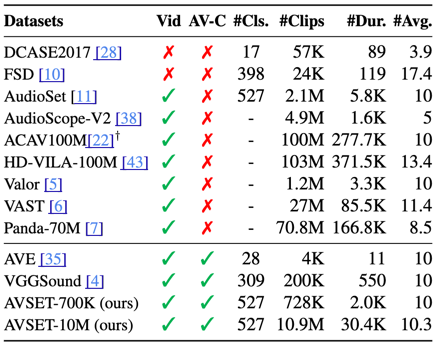
- AVSET-10M: An Open Large-Scale Audio-Visual Dataset with High Correspondence Xize Cheng, Ziang Zhang, Zehan Wang, Minghui Fang, Rongjie Huang, Siqi Zheng, Ruofan Hu, Jionghao Bai, Tao Jin, Zhou Zhao Under Review
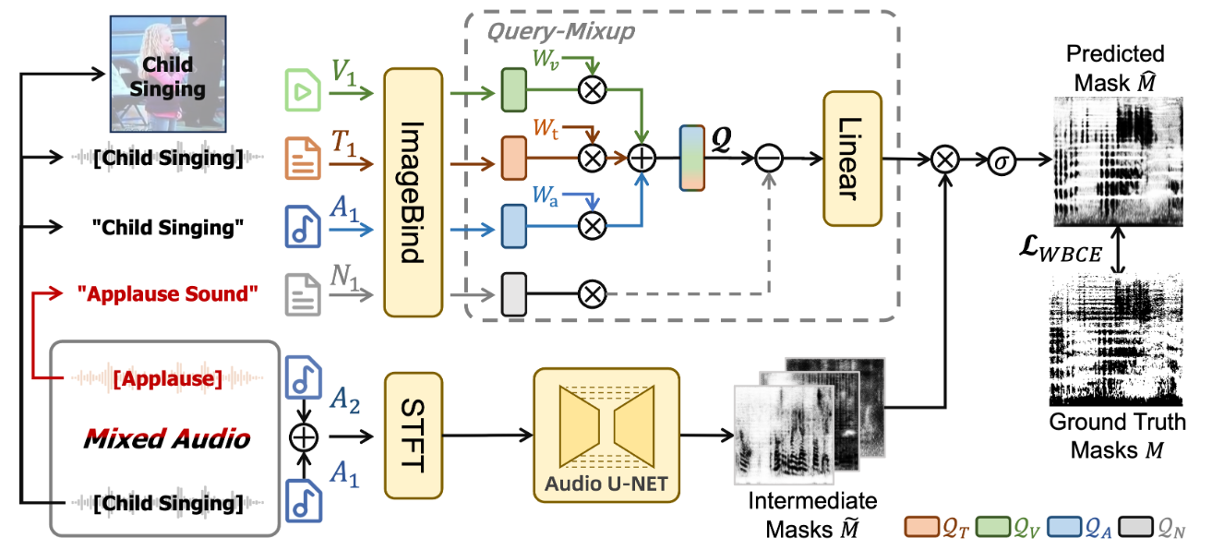
- OmniSep: Unified Omni-Modality Sound Separation with Query-Mixup Xize Cheng, Siqi Zheng, Zehan Wang, Minghui Fang, Ziang Zhang, Rongjie Huang, Ziyang Ma, Shengpeng Ji, Jialong Zuo, Tao Jin, Zhou Zhao Under Review
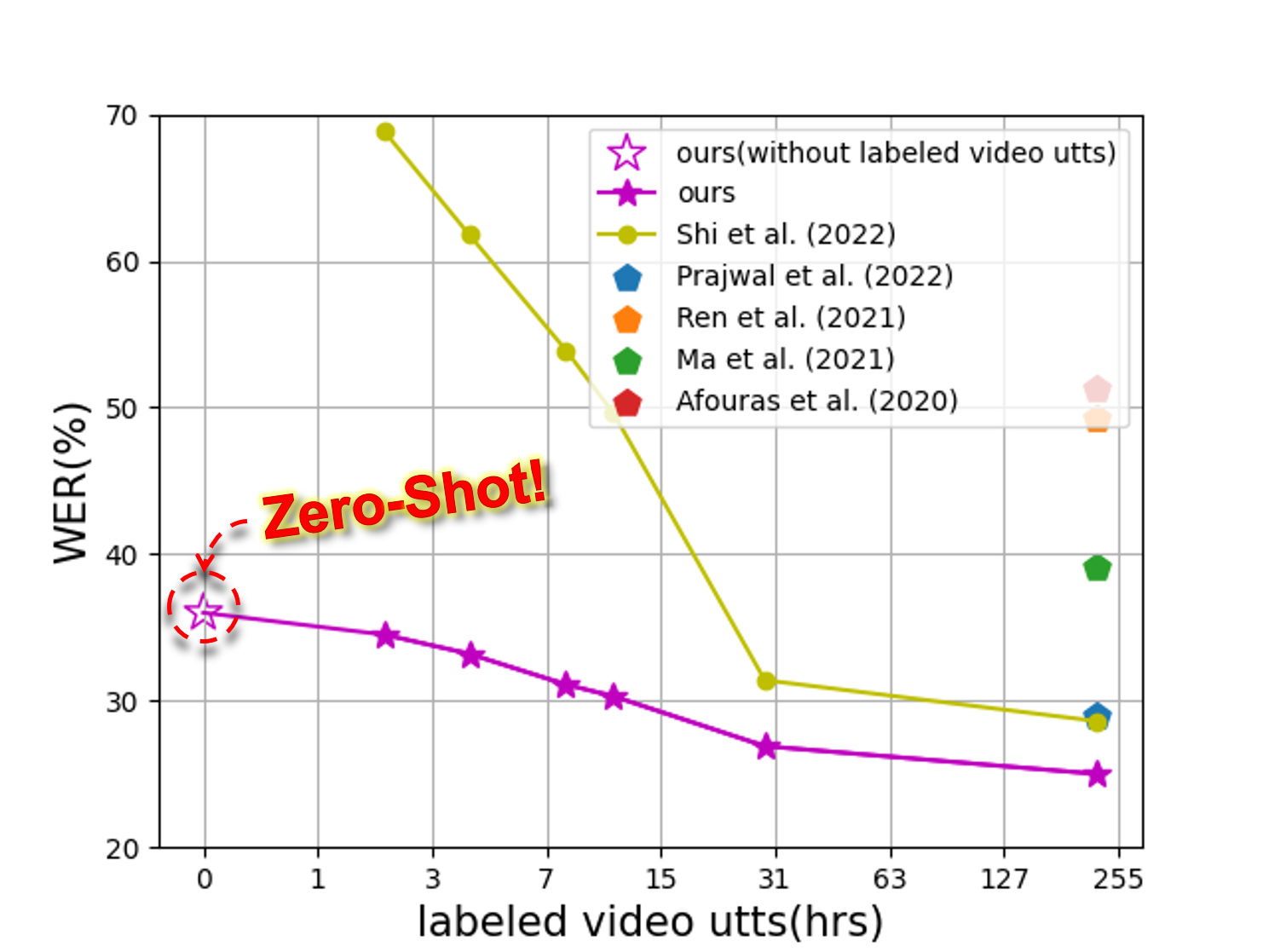
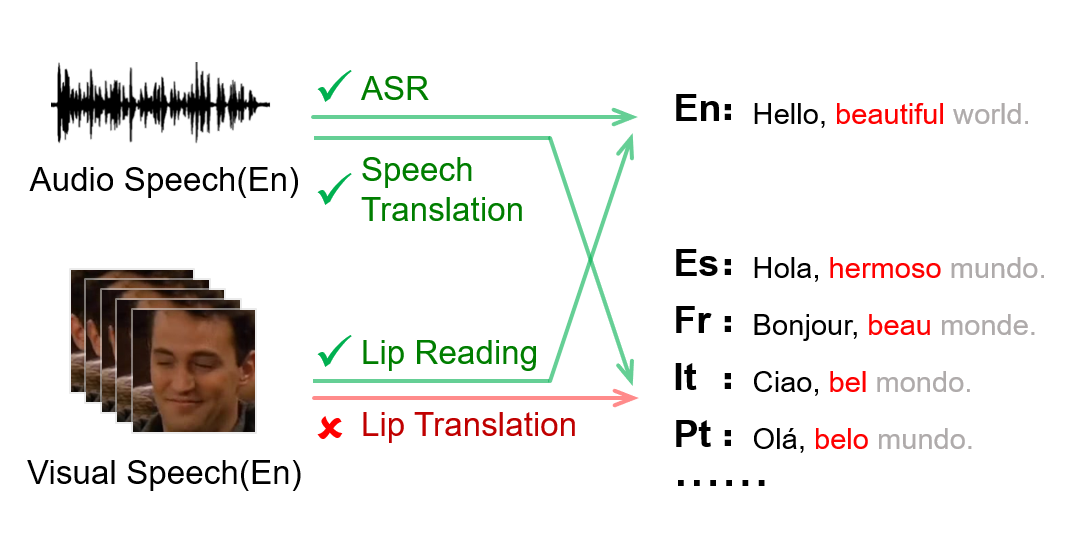
- OpenSR: Open-Modality Speech Recognition via Maintaining Multi-Modality Alignment Xize Cheng, Tao Jin, Linjun Li, Wang Lin, Xinyu Duan, Zhou Zhao ACL2023(Oral)
- MixSpeech: Cross-Modality Self-Learning with Audio-Visual Stream Mixup for Visual Speech Translation and Recognition Xize Cheng, Tao Jin, Rongjie Huang, Linjun Li, Wang Lin, Zehan Wang, Huadai Liu, Ye Wang, Aoxiong Yin, Zhou Zhao ICCV2023
- AV-TranSpeech: Audio-Visual Robust Speech-to-Speech Translation Rongjie Haung*, Xize Cheng*, Huadai Liu*, Yi Ren, Linjun Li, Zhenhui Ye, Jinzheng He, Lichao Zhang, Jinglin Liu, Xiang Yin, Zhou Zhao ACL2023
Full Publication List
[*] denotes co-first authors, [#] denotes co-supervised, [✉] denotes corresponding author,
Spoken Dialogue System & Audio-Visual Speech Understanding
-
ICLR2025VoxDialogue: Can Spoken Dialogue Systems Understand Information Beyond Words? Xize Cheng, Ruofan Hu, Xiaoda Yang, Jingyu Lu, Dongjie Fu, Zehan Wang, Shengpeng Ji, Rongjie Huang, Boyang Zhang, Tao Jin, Zhou Zhao. -
ICLR2025Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling Shengpeng Ji, Ziyue Jiang, Xize Cheng, Rongjie Huang, Yidi Jiang, Qian Chen, Siqi Zheng, Zhou Zhao, et al. -
SurveyWavChat: A Survey of Spoken Dialogue Models Shengpeng Ji, Shujie Liu, Xize Cheng, Jian Li, Yidi Jiang, Jingzhen He, Yunfei Chu, Jin Xu, Zhou Zhao, et al. -
EMNLP2024AudioVSR: Enhancing Video Speech Recognition with Audio Data. Xiaoda Yang *#, Xize Cheng*, Jiaqi Duan, Hongshun Qiu, Minjie Hong, Minghui Fang, Shengpeng Ji, Jialong Zuo, Zhiqing Hong, Zhimeng Zhang, Tao Jin. -
ACMMM2024Synctalklip: Highly synchronized lip-readable speaker generation with multi-task learning Xiaoda Yang *#, Xize Cheng*, Dongjie Fu, Minghui Fang, Jialung Zuo, Shengpeng Ji, Zhou Zhao, Jin Tao -
ACMMM2024SegTalker: Segmentation-based Talking Face Generation with Mask-guided Local Editing Lingyu Xiong #, Xize Cheng ✉, Jintao Tan #, Xianjia Wu, Xiandong Li, Lei Zhu, Fei Ma, Minglei Li, Huang Xu, Zhihui Hu. -
ACMMM2024 OralBoosting Speech Recognition Robustness to Modality-Distortion with Contrast-Augmented Prompts Dongjie Fu#, Xize Cheng, Xiaoda Yang#, Wang Hanting, Zhou Zhao, Tao Jin. -
ACL2024TransFace: Unit-Based Audio-Visual Speech Synthesizer for Talking Head Translation. Xize Cheng, Rongjie Huang, Linjun Li, Tao Jin, Zehan Wang, Aoxiong Yin, Minglei Li, Xinyu Duan, Zhou Zhao. -
ACL2024Uni-Dubbing: Zero-Shot Speech Synthesis from Visual Articulation. Songju Lei #, Xize Cheng ✉, Mengjiao Lyu, Jianqiao Hu, Jintao Tan #, Runlin Liu, Lingyu Xiong #, Tao Jin, Xiandong Li, Zhou Zhao. -
ICCV2023MixSpeech: Cross-Modality Self-Learning with Audio-Visual Stream Mixup for Visual Speech Translation and Recognition. Xize Cheng, Tao Jin, Rongjie Huang, Linjun Li, Wang Lin, Zehan Wang, Huadai Liu, Ye Wang, Aoxiong Yin, Zhou Zhao. -
ACL2023AV-TranSpeech: Audio-Visual Robust Speech-to-Speech Translation. Rongjie Haung*, Xize Cheng*, Huadai Liu*, Yi Ren, Linjun Li, Zhenhui Ye, Jinzheng He, Lichao Zhang, Jinglin Liu, Xiang Yin, Zhou Zhao. -
ACL2023Contrastive Token-Wise Meta-Learning for Unseen Performer Visual Temporal-Aligned Translation. Linjun Li*, Tao Jin*, Xize Cheng*, Ye Wang, Wang Lin, Rongjie Huang and Zhou Zhao.
Multi-Modal Alignment
-
Under ReviewAVSET-10M: An Open Large-Scale Audio-Visual Dataset with High Correspondence Xize Cheng, Ziang Zhang, Zehan Wang, Minghui Fang, Rongjie Huang, Siqi Zheng, Ruofan Hu, Jionghao Bai, Tao Jin, Zhou Zhao. -
ICLR2025OmniSep: Unified Omni-Modality Sound Separation with Query-Mixup Xize Cheng, Siqi Zheng, Zehan Wang, Minghui Fang, Ziang Zhang, Rongjie Huang, Ziyang Ma, Shengpeng Ji, Jialong Zuo, Tao Jin, Zhou Zhao. -
ICML2024Omnibind: Large-scale omni multimodal representation via binding spaces Zehan Wang, Ziang Zhang, Hang Zhang, Luping Liu, Rongjie Huang, Xize Cheng, Hengshuang Zhao, Zhou Zhao -
NIPS2023Connecting Multi-modal Contrastive Representations. Zehan Wang, Yang Zhao, Xize Cheng, Haifeng Huang, Jiageng Liu, Li Tang, Linjun Li, Yongqi Wang, Aoxiong Yin, Ziang Zhang, Zhou Zhao. -
ACMMM2023Rethinking Missing Modality Learning from a Decoding Perspective. Tao Jin *, Xize Cheng *, Linjun Li, Wang Lin, Ye Wang, Zhou Zhao. -
ACL2023 OralWeakly-Supervised Spoken Video Grounding via Semantic Interaction Learning. Ye Wang, Wang Lin, Shengyu Zhang, Tao Jin, Linjun Li, Xize Cheng and Zhou Zhao. -
ACL2023 OralOpenSR: Open-Modality Speech Recognition via Maintaining Multi-Modality Alignment. Xize Cheng, Tao Jin, Linjun Li, Wang Lin, Xinyu Duan, Zhou Zhao.
📖 Educations
-
2021.09 - 2026.06, Doctor, Zhejiang University, Hangzhou.
-
2017.09 - 2021.06, Undergraduate, Shandong Univeristy, Jinan.
🎖 Honors and Awards
- National Scholarship (2023, Grauate student). Top 0.1% in Zhejiang University.
- Excellent Graduate, Shandong Province (2021), Top 1%.
- Outstanding Student Cadres (2017-2021 in Shandong University and 2021-2023 in Zhejiang University), Top 1%.
- Academic Scholarship (2017-2021 in Shandong University and 2021-2023 in Zhejiang University), Top3%.
- Outstanding Graduate Student & Triple Excellence Graduate Student(2022) in Zhejiang University.
- First Prize (Meritorious Winner) in American Mathematical Modeling Competition (2019), Top 7% worldwide.
- First Prize of National Mathematical Modeling Competition in Shandong Province (2018).
💬 Professional Services
- Conference Reviewer: ARR 2023, ICCV 2023, ACL 2023
- Assist to Review: KDD 2022, TNNLS 2022, TMM 2022, TMM 2023
💻 Internships & Projects
- 2024.01- 2024.09: Research Intern: Alibaba, DAMO Academy, Tongyi Lab at Hangzhou, China.
Research on Audio-Visual Sound Separation and Spoken Dialogue System.
- 2021.02 - 2021.08: Algorithm Engineer Intern: Taobao(China) Software
Research on Multi-modality Interaction.
